

Recently, we submitted our formal response to the Request for Information on the Development of an Artificial Intelligence (AI) Action Plan by the National Science Foundation. Our recommendations were grounded in the belief that advancing AI capabilities is inseparable from national security and operational resilience. AI systems will increasingly underpin defense readiness, intelligence, logistics, and mission-critical decision-making. But ambition alone is not enough. Without a structured, quantifiable approach to AI development, even the most promising initiatives risk falling short of their potential.
The most persistent obstacle to scaling effective AI is not a lack of talent or funding—it’s ambiguity. Across the lifecycle of AI systems, from data collection to model deployment, decisions are too often made without a clear understanding of how each component contributes to mission outcomes. Training failures, bias, and performance degradation don’t usually stem from one obvious mistake. They emerge from the accumulation of small missteps—mislabeled data, misaligned taxonomies, or evaluation processes that surface issues too late to correct them cost-effectively.
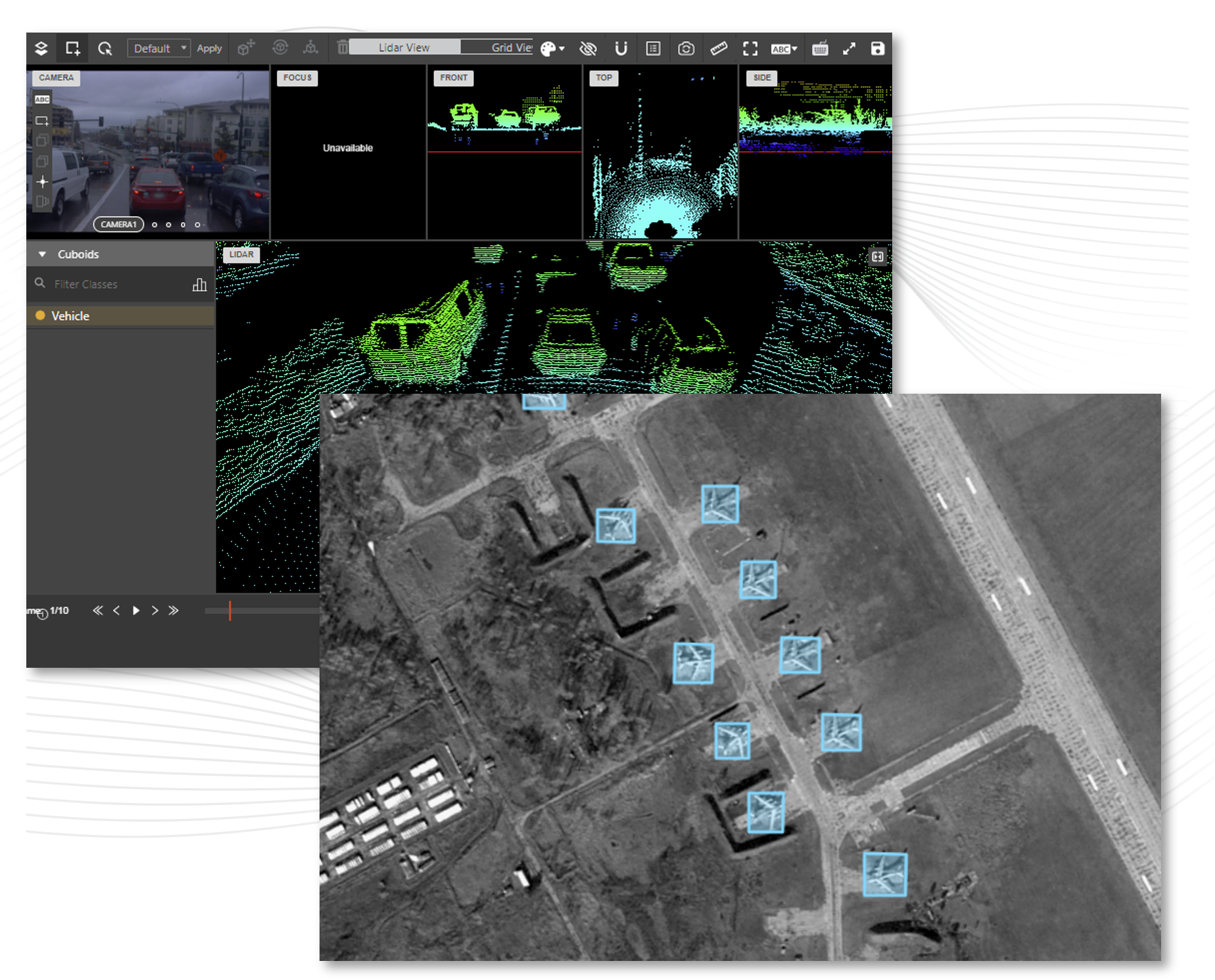
A central theme of our submission is the critical need to embed quantifiable metrics across the entire AI development pipeline. In many programs today, metrics are sparse, siloed, or introduced only at the final stages. But by the time a model is deployed, inefficiencies may already be deeply embedded. A mislabeled dataset can distort learning. An inflexible ontology can limit generalization. A test set built around static benchmarks can mask how a model will perform under dynamic, real-world conditions. When performance degradation surfaces months after deployment, it’s not a failure of the model—it’s a failure of oversight.
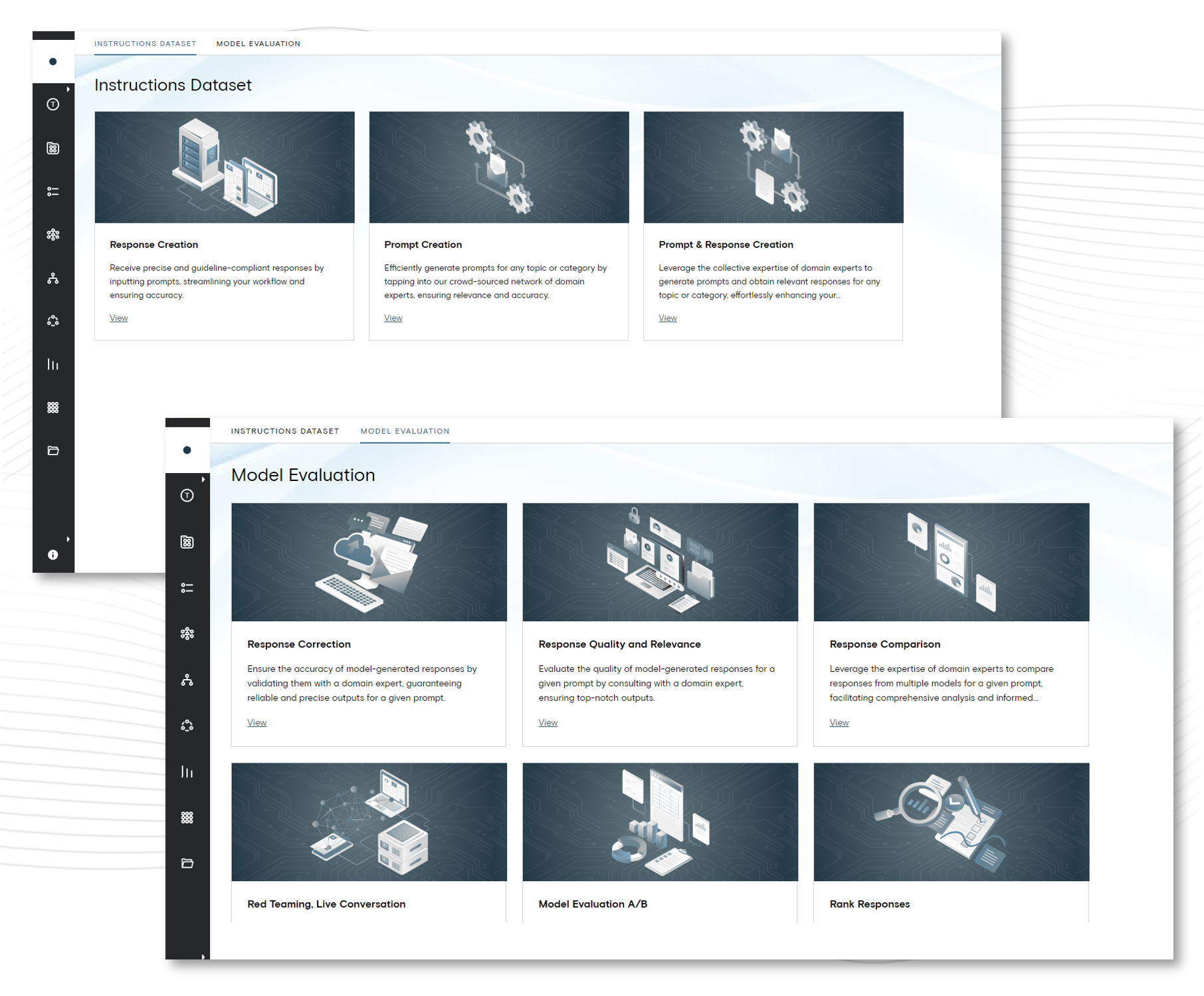
To address this, we propose a development model grounded in continuous measurement and iterative refinement. Each stage of the AI lifecycle—data sourcing, annotation, model training, and evaluation—should be assessed with metrics that reflect real-world mission relevance. Rather than measuring success solely against static validation datasets, performance should be evaluated on adaptability, resilience to edge cases, and consistency across evolving operational domains. These aren’t just nice-to-have characteristics—they are foundational requirements for AI to be effective at scale.
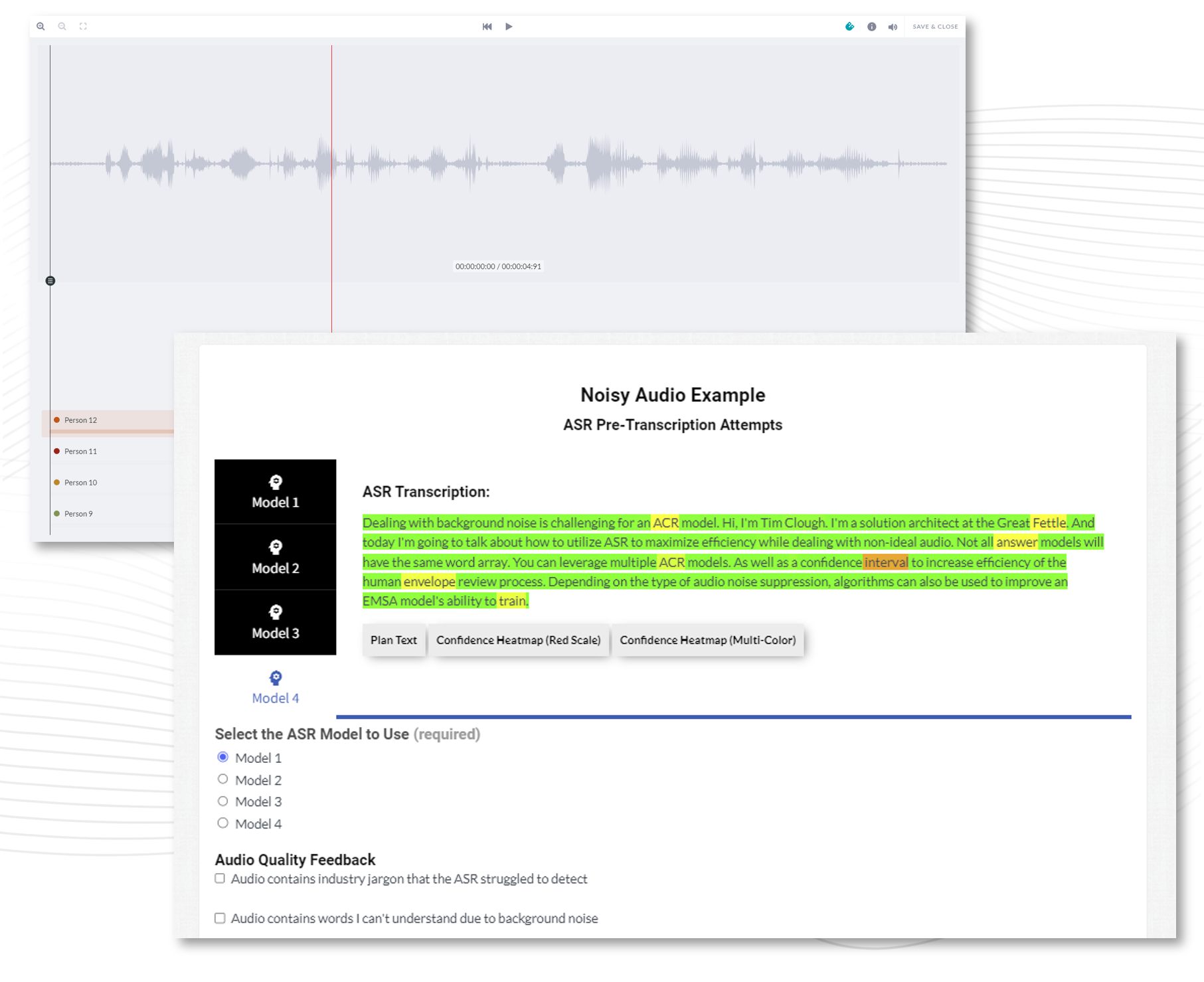
Annotation quality, in particular, remains one of the most overlooked factors in AI system performance. Inconsistent labels or vague ontologies introduce cognitive noise that cannot be corrected with more data or larger models. Without quantitative quality metrics with full transparency in AI training data, AI researchers are left to learn from distorted inputs. A high-performing model trained on poor data is still a poor system—it just fails more confidently.
Unlocking AI innovation requires managing risk in AI systems. It requires shifting from reactive fixes to proactive prevention. Instead of treating evaluation as a checkpoint at the end, it should operate as a continuous feedback loop—surfacing anomalies, monitoring for drift, and identifying vulnerabilities as they emerge. Importantly, this also applies to the data and labeling pipelines. Errors in these early stages don’t just affect one model—they propagate across systems, skewing performance metrics and reinforcing flawed assumptions.
Procurement structures play a critical role in enabling or limiting this type of continuous innovation. Long-term, single-award contracts can constrain flexibility, particularly when performance is tied to static deliverables. It’s essential to build in safeguards on single award contracts: structured incentives tied to performance gains, transparency into development processes and metrics, and contract terms that allow for adaptation as technology and mission needs evolve. Where possible, multi-award, shorter-duration contracts can promote agility and foster competition across different components of the AI lifecycle—whether in data labeling, model development, or evaluation tooling.
Ultimately, unlocking AI innovation isn’t just about building bigger models—it’s about building better AI programs that enable innovation to surface quickly. Programs that are traceable, auditable, and aligned with evolving mission realities. This requires more than algorithmic breakthroughs; it demands operational frameworks where measurement is embedded from the start, and where improvement is not episodic but continuous.
The future of AI in national security hinges on disciplined, data-driven development. With the right metrics in place, performance can be understood, refined, and optimized—not assumed. Innovation is not inhibited by oversight—it is accelerated by clarity. And with a quantifiable blueprint guiding every investment, the AI systems of tomorrow won’t just work—they’ll keep getting better.
Read our full AI Action Plan here.