

In the world of machine learning, it’s easy to get obsessed with model architecture, training tricks, and GPU specs. But there’s another ingredient that often gets overlooked—and it might be costing you time and money: the type of annotation used for training data.
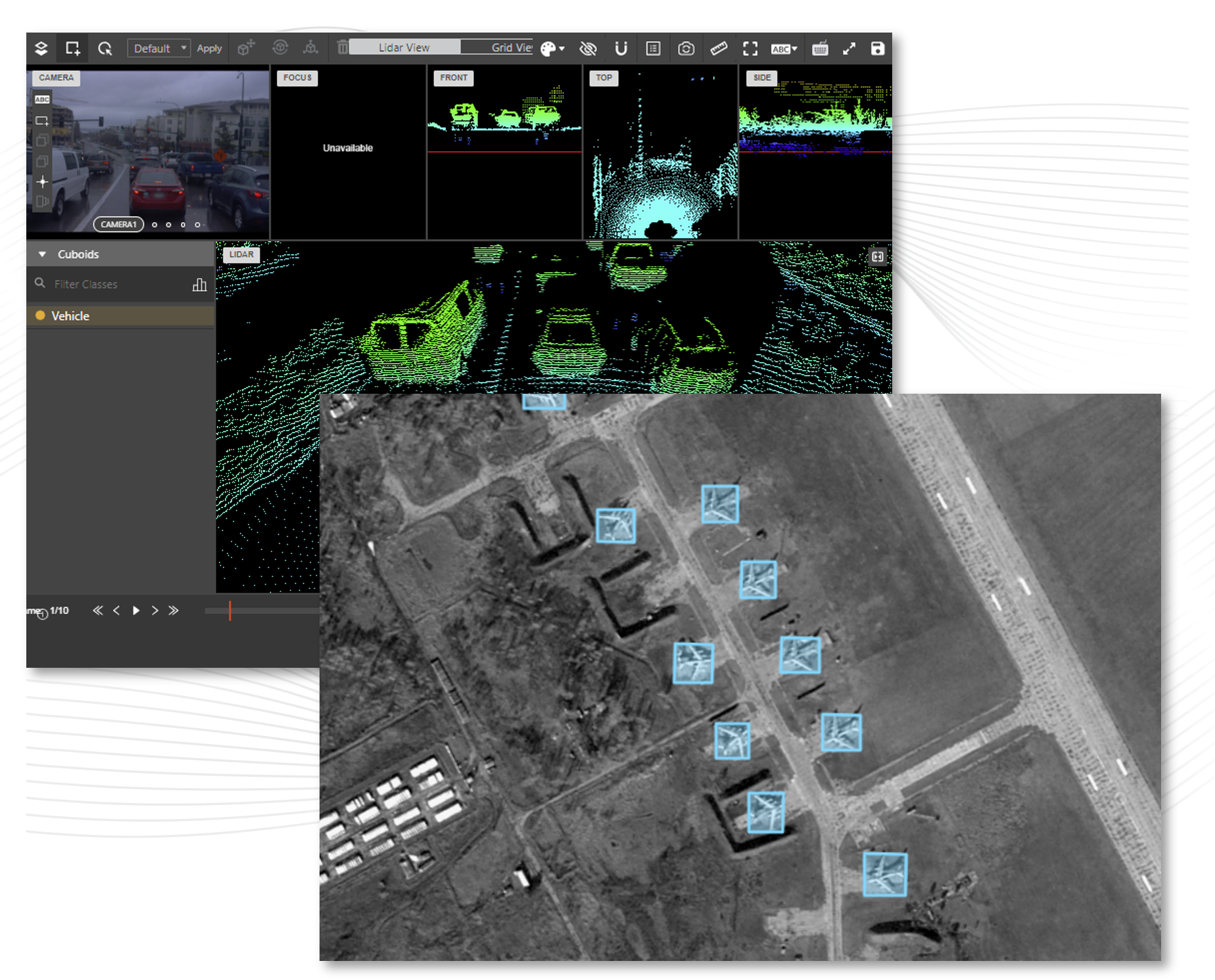
In a recent study my co-authors and I presented at CVPR*, we explored a deceptively simple question: Does the way we annotate objects in images—polygons, bounding boxes, or simple point markers—actually affect model performance? For example, if we wanted to build an airplane detector, which one of the annotation types in Figure 1 would produce the best ML results?

FIgure 1
Illustration of different annotation types (a) polygon, (b) bounding box, (c) oriented bounding box, (d) point target or target centroid. Imagery copyright Maxar.
For the experiment, we trained three identical neural networks to detect vehicles in satellite images, each using a different annotation method. Then we compared not just the results, but the cost to get there.
As expected, the model trained on polygon annotations—the most detailed and expensive type—performed best. But the others weren’t far behind. When we evaluated all networks using high-fidelity polygon annotations as the reference standard, the performance gap narrowed considerably. This showed that even models trained on coarser annotations were still learning to detect objects in a way that closely resembled the actual shapes.
Even more interestingly, the models didn’t simply reproduce the geometry of their annotations. Instead, they learned to localize objects in a consistent and meaningful way across all annotation types. Sure, the bounding box and centroid-trained models showed a few more false positives, but their detection patterns looked surprisingly similar to those from the polygon-trained model.
While our original paper highlighted the substantial differences in manual annotation time and associated cost between methods, that context has shifted significantly. First, this research is now six years old—and in that time, both annotation tooling and AI-assisted labeling have made dramatic leaps forward. In particular, foundation models like Meta’s Segment Anything 2 have radically accelerated our ability to produce quality polygons. What once took minutes per object can now take seconds (or less). That said, annotation time is still highly dependent on the ontology. Complex objects with fine-grained structure or more vertices will always demand more precision and time, regardless of the toolset.
Our takeaway: if you’re labeling data for an object detection task, don’t automatically default to the most complex annotation. Consider the trade-offs. At Figure Eight Federal, we can provide you advice and guidance on the best way to craft your dataset for optimal ML model performance.
* “Comparing the Effects of Annotation Type on Machine Learning Performance”, Mullen, J., Tanner, F., Sallee, P., IEEE Computer Vision Pattern Recognition Workshop on Perception Beyond the Visible Spectrum 2019