
-
 Geospatial Data
Geospatial Data -
 Natural Language Processing
Natural Language Processing
Intelligence
Our Unparalleled Offerings Include:
Know Where You Are Looking With Precision.
Know where you are looking with precision. Figure Eight Federal’s landmark tagging tool leverages Dot Detection to label and identify landmarks on objects. Our tagging solution powers landmark annotation of image content based on user-customizable ontologies. Dot detection also identifies multiple image content classes from your custom ontology and then trains your data models using key points in the imagery, thereby increasing efficiency and robustness.
Track objects faster. Traditional methods of object tracking require videos to be split into frame-by-frame sequences meaning every frame must be hand-annotated to effectively train a model. Figure Eight Federal’s Linear Interpolation and Machine Learning assisted video object tracking model predicts the position of objects and automatically tracks them, reducing contributor fatigue and increasing productivity. Figure Eight Federal’s Video Object Tracking capability leverages a cutting-edge ensemble of Machine Learning models, and patented technology, to label videos up to 100 times faster than human-only approaches.
Turn Audio Clips Into Precise Text.
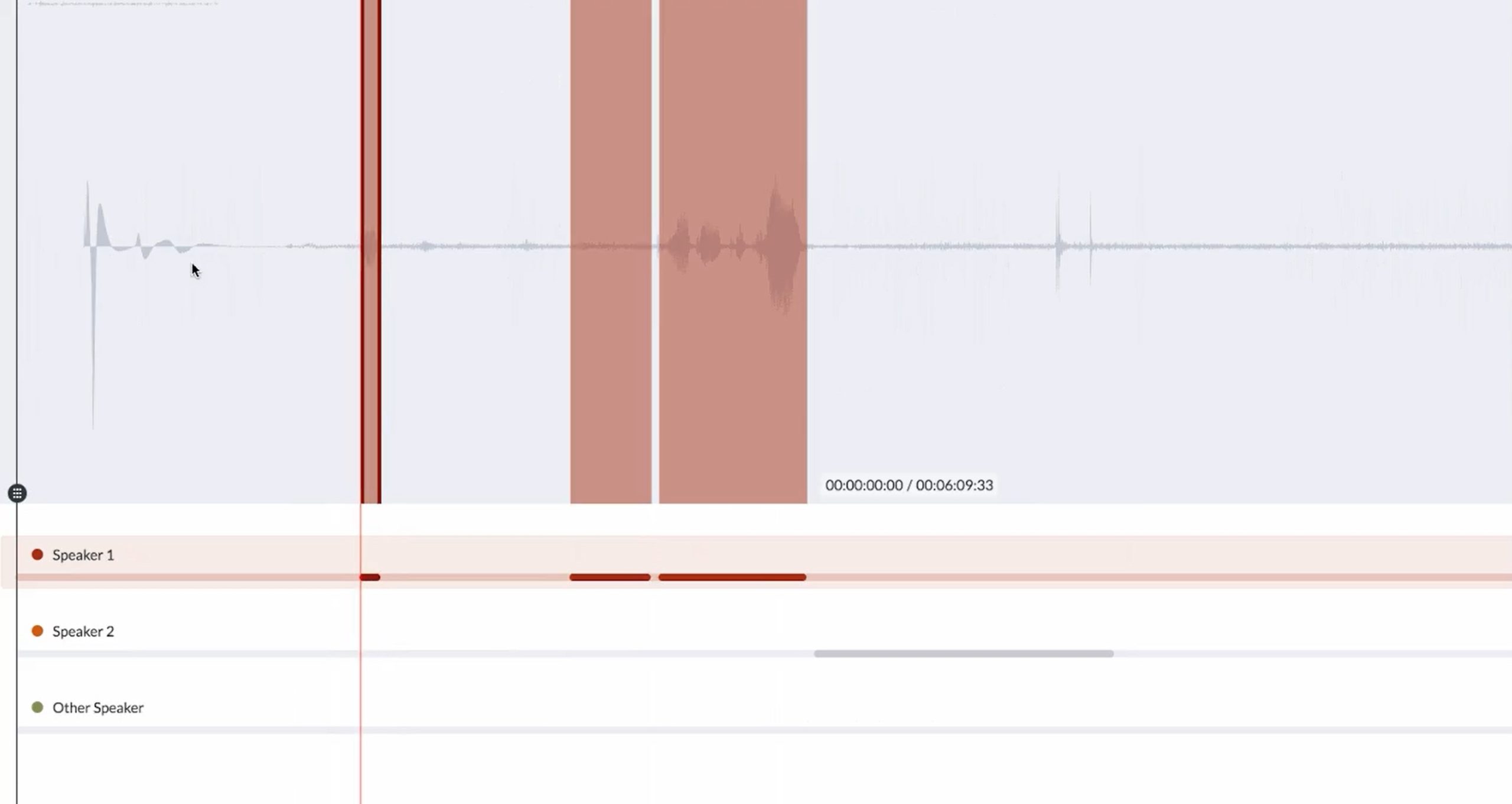
Optimal understanding of audio clips often requires that the audio be transformed into written text. Figure Eight Federal’s platform provides free-text translation from audio utterances, with a multi-step workflow for maximum accuracy and quality. We provide transcription (or recording) by native speakers in whatever languages you require. We deploy specific pools of analysts vetted with a variety of security clearances.
Create, label, and validate domain-specific text data in a wide array of languages–including Arabic. With our Document Exploration (DOMEX) offering, secure precise Sentiment Analysis, Text Annotation, Intent Classification, and Utterance Collection. Through our NLP transcription, Figure Eight Federal clients have gained a per-unit efficiency of 29%.
Other Figure Eight Federal Solutions


Get Started
Fully customizable AI solutions will help your organizations work faster and with more accuracy.