
Building Computer Vision Models at Scale
There are certain steps necessary to train a computer vision model at scale. Keep reading for best practices that companies can apply to a variety of computer vision projects.
What is Computer Vision?
Computer vision is a field of artificial intelligence that trains computers to interpret and understand the visual world. In the last three years, real-world applications of computer vision have gained traction thanks to ample access to images and videos, computing power, and advanced data infrastructure. These breakthroughs have allowed computer vision to span across industries, including automotive, healthcare, agriculture, and finance.
How to Think About and Build an Algorithm
Humans use their eyes and brains to analyze their surroundings. Computers achieve this through algorithms trained on loads of data. A computer properly trained on all visual nuances can outperform a human in many instances. Why?
Computers can:
- process and analyze myriads of information
- avoid biases with proper training
- simplify and quickly perform certain processes
- free up resources for tasks where human interaction is more critical
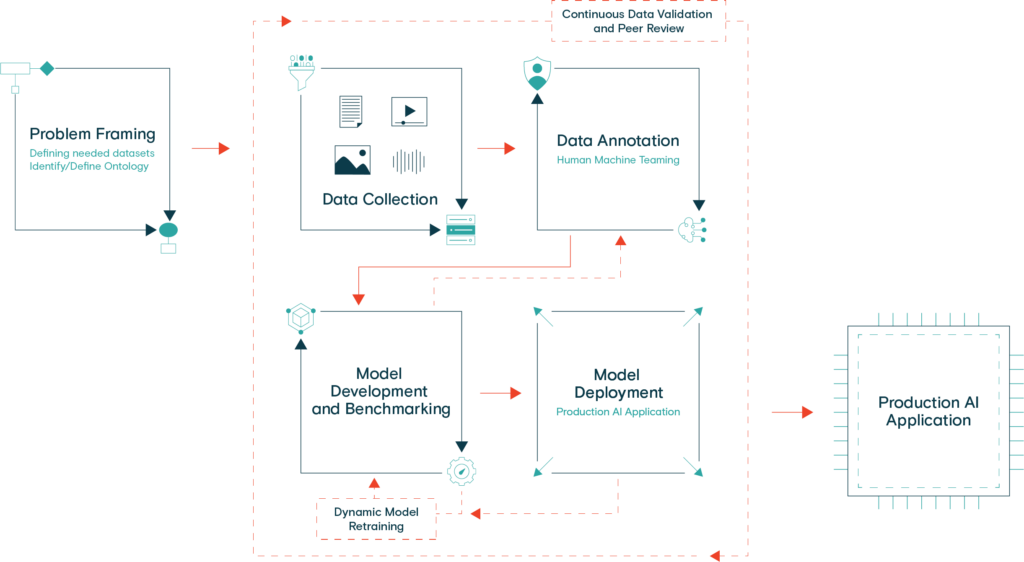
Three critical components to build a successful computer vision algorithm include the process, data, and project management.
Process
At Figure Eight Federal, we work with a number of federal clients who are actually running computer vision projects – and getting value out of it. Our most successful clients follow this disciplined process to launch and iterate their initiatives:
- Business Problem: definition, value, stakeholders, priority, investment
- Data: availability, provenance, security, coverage, cleaning, augmentation, annotation, refreshing pipeline, development
- Model Building: feature extraction, hyperparameters, tuning, selection, benchmarking
- Deploy and Measure: business value measurement, AB testing, versioning, business process integration
- Learning and Tuning: bias mitigation, ground truth, and success monitoring, version control
Training Data
When it comes to training data, a well-defined data strategy and ML data pipeline are key. A typical machine learning training pipeline many ML teams use to start building projects follows a basic flow.
- Start with a data set that is available to them
- Spend time to clean and organize the data set
- Build a model
- Train the model using the cleaned and organized data set
- Validate the model
- Deploy at scale
While open-source datasets are a good starting point when you are looking to get started with ML on simple models or side projects, they are often not for real-world applications. You need something that works precisely for your use case, and a generic dataset will not help.
When approaching training data, consider why you’re making a computer vision model, and how important accuracy is. If you are making a computer vision model to gain a competitive edge, you can differentiate only by collecting proprietary training data like the data you expect your final model to work well on.
If accuracy is critical to your computer vision model (and if you’re aiming for success, it should be), there is a direct correlation of model quality and accuracy with the amount of high-quality training data that you expose to your model.
Regardless of your computer vision model, you will need a lot of training data, and for a successful model, you will need data that is created specifically for your use case.
Project Management
Discussing computer vision project management reveals a lot of unanswered questions around roles, responsibilities, and team structure. For example, who determines training data requirements, project managing, providing budget, overseeing quality, or training and tuning?
For training data, it’s critical to have someone who understands the business goal and the problem at hand. This person works with data scientists to define and prioritize the training data needs. Someone else will need to manage the project and champion the necessity and budget for the work. Still, another person will be required to take responsibility for quality assurance, defining quality goals, auditing and monitoring the models, and tracking benchmarks.
At Figure Eight Federal, we have Federal clients who are developing complex computer vision initiatives and those just getting started in AI. The typical roles we see managing these tasks include an executive sponsor, owner or project manager, data scientist, ML engineer, and QA with quality responsibilities.
Other important project management considerations include:
- Precise data collection requirements
- Sourcing data
- Data labeling requirements
- Budget and time
Computer Vision Data Annotation
There are several different types of data you may want to annotate. Examples include images (with or without localization), Pixel-Level Semantic Segmentation, OCR (optical character recognition) Transcription, Machine Learning assisted Video Object Tracking, and 3D Point Cloud (LiDAR – Light Detection and Ranging) annotation. With each of these, specialty tools can be useful.
Image classification
It involves assigning a label to an entire image or photograph. Look for a tool where you can create high-quality instructions easily, have robust quality control, and is customizable to support a variety of question types and visualization options.
Image classification with localization
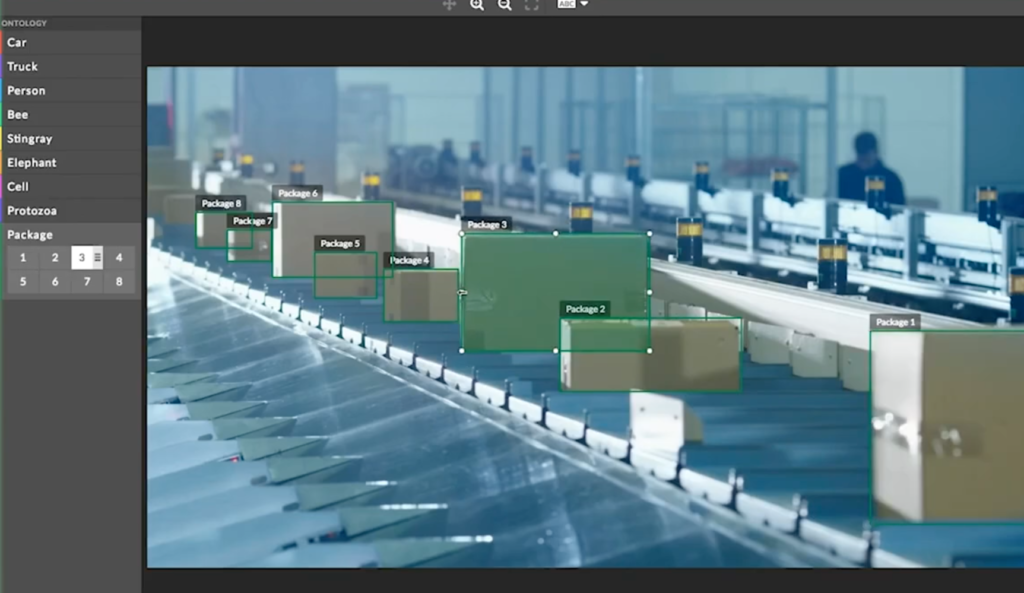
It involves assigning a class label to an image and showing the location of the object in the image by a shape (e.g., drawing a box around the object). Specialty tools should support different shapes so you can annotate complex scenes, excel in quality control features, and be a flexible toolkit that can be modified based on your use case.
Pixel-level semantic segmentation
It’s the task of object detection draws a line around each object detected in the image, identifying the specific pixels in the image that belong to the object. This time-consuming task will benefit from a toolkit that supports different labeling mechanisms for different object types. This can also be simplified with ML algorithms to do some groundwork for annotator efficiency. It’s also worth mentioning that a workforce comprised of skilled annotators will help this complex task.
OCR
They are models developed for either consumer offerings or, to speed up their own internal processes. At Figure Eight Federal, our ML assisted transcription tool uses a machine learning model to transcribe first, with human annotators approving and correcting the transcription second. This approach significantly improves the speed and quality of your training data output.
ML assisted Video Object Tracking
They are computer vision models on video data that deals with not one image, but hundreds of frames for a single video clip. You will require a tool that supports machine assistance. Otherwise, annotation tasks will quickly become cost prohibitive. The Figure Eight Federal Video Object Tracking tool works by having contributors annotate objects in a frame, then leverage Figure Eight Federal Machine Learning model to persist that annotation across subsequent frames, showing 100X efficiency gain over human-only solutions.
3D Point Cloud (LiDAR)
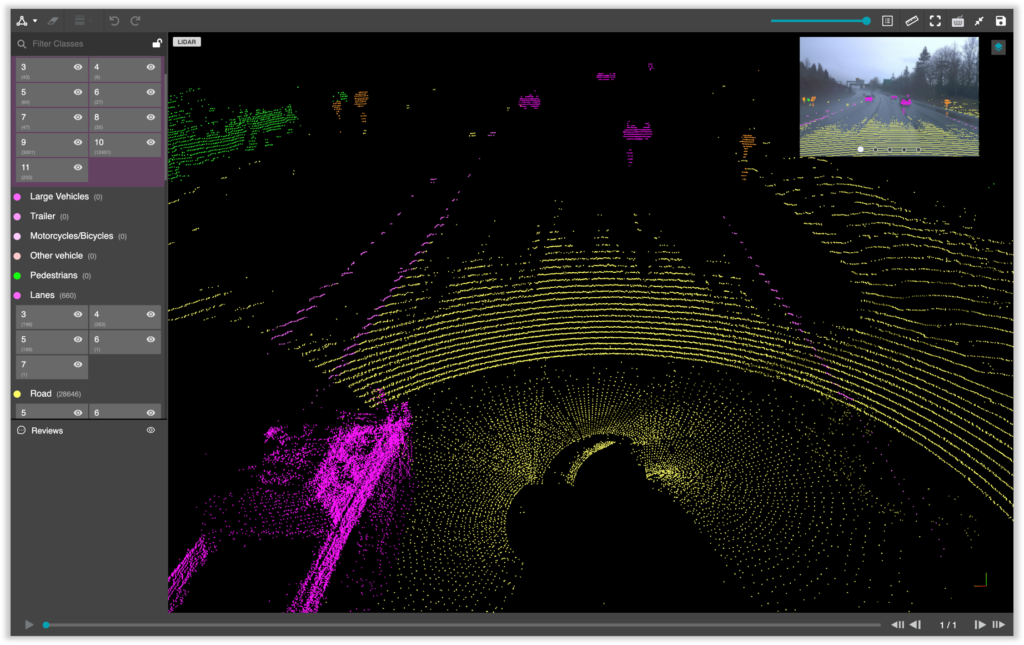
It relies on light in the form of a pulsed laser to measure variable distances. LiDAR annotation can be tricky because a LiDAR point cloud is usually sparse and has low resolution, making it difficult for human annotators to recognize objects. Compared to annotation on 2D images, the operation of drawing 3D bounding boxes or even point-wise labels on LiDAR point clouds is more complex and time-consuming. Additionally, LiDAR data is usually collected in sequences, so consecutive frames are highly correlated, leading to repeated annotations.
The ideal point cloud annotation tool will label UI in a way that is intuitive enough for a non-LiDAR expert to use. This tool should also utilize Machine Assistance in the annotation process. Thus, it would support a range of data types and sizes, feature data security and privacy, and provide access to skilled workers trained to provide high quality and consistent annotation.
When it comes time to train and tune your computer vision models at scale, schedule a demo to learn more about how Figure Eight Federal will bring your AI project from Pilot to Production.