
Using AI for Impactful Decisions
Artificial Intelligence (AI) is transforming the Federal Government: driving down costs, maximizing revenue, and enhancing decision accuracy. And many agencies are taking notice: The AI market size is expected to grow to $390.9 billion by 2025, and industries within the space show a similar trend—automotive AI, for example, is expected to grow by 35% year over year, and manufacturing AI will likely increase by $7.22 billion by 2023. We see organizations accelerating their adoption of AI projects as well, with Gartner reporting that the average company adopted four AI projects in 2019 and is expected to adopt thirty-five in 2022.
Even with this immense growth, challenges in deploying AI remain. According to top industry analysts, most (about 80%) of AI projects stall at the pilot phase or proof-of-concept phase, never reaching production. In many cases, this is due to a lack of high-quality data. Ethics and responsible AI continue to be obstacles for many initiatives, which often lack the resources or internal experience to build unbiased models in a time where AI is making increasingly impactful decisions. Companies also face an uphill battle with scaling and automation; while tech leaders are keen to apply DevOps principles to AI, they still struggle with architecting a solution for automating end-to-end machine learning (ML) pipelines.
Developing the right tools and strategies upfront will help overcome these challenges, giving agencies the confidence to deploy and the potential to grow.
Components of a Seamless Machine Learning Pipeline
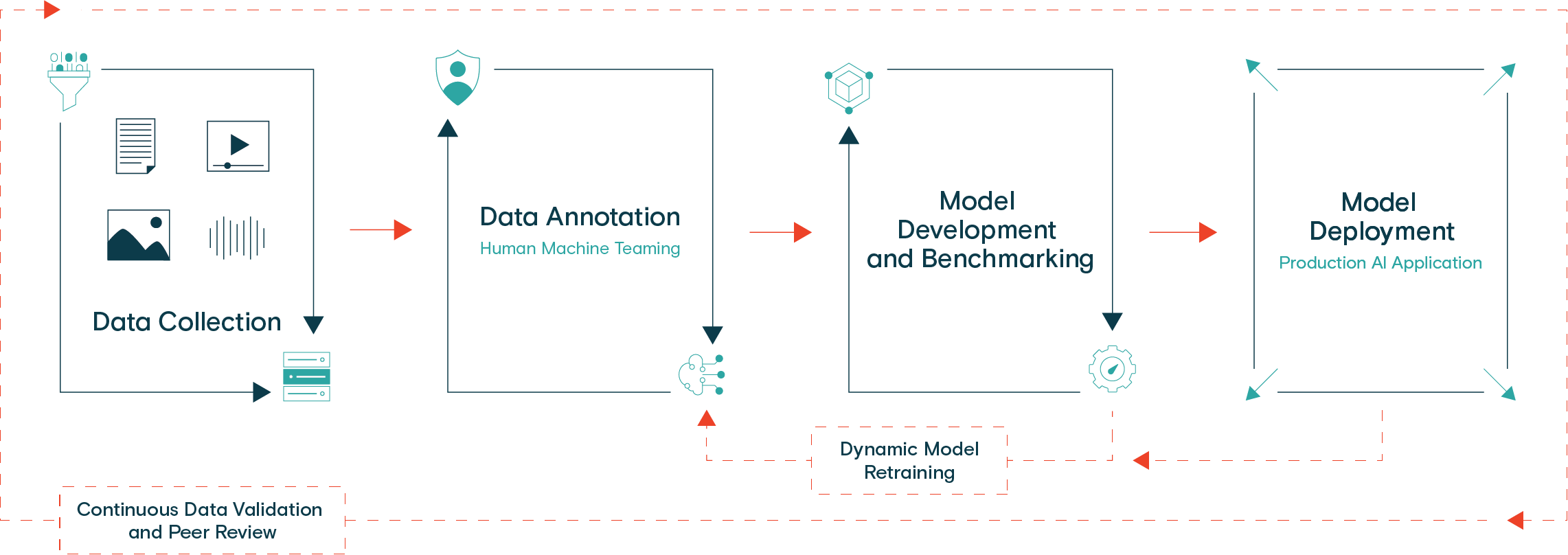
The key to developing AI from Pilot to Production: it is all in the data. High-quality training data is needed to launch effective models. Defining your data strategy upfront, including what your data pipeline will look like, will be crucial to success. To illustrate, let’s walk through a healthy ML pipeline:
Data Collection and Annotation
Many data scientists and machine learning engineers say that about 80% of their time is spent wrangling data. That is a heavy uplift, but a model cannot work without training data. The model build process, then, starts with collecting and labeling training data.
You should start with a clear strategy for data collection. Think about the use cases you are targeting and ensure your datasets represent each of them. Have a clear plan for collecting diverse datasets. For example, if you are building AI for a fully autonomous vehicle, your data needs to represent different geographies, weather, and times of the day.
Next, you will want to implement your data annotation process, which in most cases, requires a diverse crowd of human annotators. The more accurate your labels, the more precise your model’s predictions will ultimately be. Various perspectives will enable you to cover a broader selection of use and edge cases.
At the data collection and annotation phase, it is critical to have the right plan for tooling in place. Be sure to integrate quality assurance checks into your processes as well. Given that this step takes up most of the time spent on an AI project, it is especially helpful to work with a data partner in this area.
Model Training and Validation
When your training data is ready, train your model using that data. Most ML models leverage supervised learning, which means you need humans to provide ground truth monitoring. They check to make sure the model is making accurate predictions. This is often a critical phase, but is a lighter lift. If the model is not working in this phase, go back and ensure your training data is truly the right data you need. Optimize with a focus on the business value that this model is supposed to bring.
Model Deployment and Retraining
Once your model reaches the desired accuracy levels, you are ready to launch. Post-deployment the model will start to encounter real-world data. Continue to evaluate the model’s output; if it fails to output the correct data, loop that data back through the validation phases. It is helpful to keep a human-in-the-loop to manually check a model’s accuracy and provide corrected feedback in the case of low-confidence predictions or errors.
Remember to tune your model regularly after deployment. According to McKinsey, 33% of live AI deployments require “critical” monthly data updates to maintain accuracy thresholds as market conditions change. A State of AI eBook found that 75% of organizations said that they must update their AI models at least quarterly. Regardless, every model should be continuously monitored for data drift to ensure it does not become less effective over time or even obsolete.
ML Pipelines: Critical for Taking AI from Pilot to Production
Developing an automated, integrated, and scalable data and model pipeline will help you increase your delivery speed and confidence in your models. There are many critical steps to ensuring your model is successful, but one of the biggest is ensuring your training data is accurate.
With the amount of time spent on the data collection and annotation, and the need for regular retraining and optimizing, even the biggest AI leaders turn to data partners. Data partners reduce the amount of time your team spends on this part of the model building process as well as help QA your model to ensure it remains accurate as it scales.
Schedule a Demo to plan on taking your AI initiatives from Pilot to Production.