
What is OCR?
OCR, or Optical Character Recognition, transforms documents of non-text data (ex. an image of a street sign, a printed legal document, or a handwritten letter) and turns it into machine-readable text. This is not a new technology. The first usage was back in 1914. In fact, the United States Postal Service began employing sorting machines to read addresses on letters and packages in the 1950s and still uses the same machines from the 1980s. However, a lot has changed since then. We are constantly finding new and innovative ways to infuse deep learning into the process to not only have the OCR model read the data, but to also “comprehend” what the computer is seeing.
ML algorithms can take OCR farther by translating the analyzed text into any language. For example, tourists frequently use this technology through the Google Translate “instant camera translation” function; simply point your phone’s camera at foreign text and it simulates real-time translations. OCR turns the imagery into text data and then Natural Language Processing (NLP) translates the text in real time.
This workflow of OCR to NLP can be leveraged in many complex use cases including anomaly detection in back-office processes. OCR reads the document, NLP then understands what is important and can make inferences, such as summaries of the important pieces of information contained in the document. For example, when a person is discharged from the military, a multitude of information needs to be updated in HR, finance, legal, and other systems. Emails need to be archived and projects re-assigned to the proper people to ensure continuity of government. By harnessing OCR and NLP, those operations no longer need to be hand done by an employee, thereby increasing efficiency and accuracy.
Potential Applications
As we mentioned before, one federal agency that relies heavily on OCR is the mail service. Mail labels are a great example of a massive repository of non-text data that benefits from OCR (and could further benefit from the employment of ML algorithms, more on that later).
Mail Routing
High speed cameras that “read” the addresses and barcodes on mail are used to automatically route each piece of mail to the correct location and indicate when a forwarding address or return to sender is needed. This allows the employees to focus on any mail the algorithm flags as needing human review due to being faulty or illegible addressing.
Check out this video from the USPS in the 70s that explains their sorting process. Then compare it to this video from the USPS in 2014; the processes are nearly identical!
USPS Informed Delivery
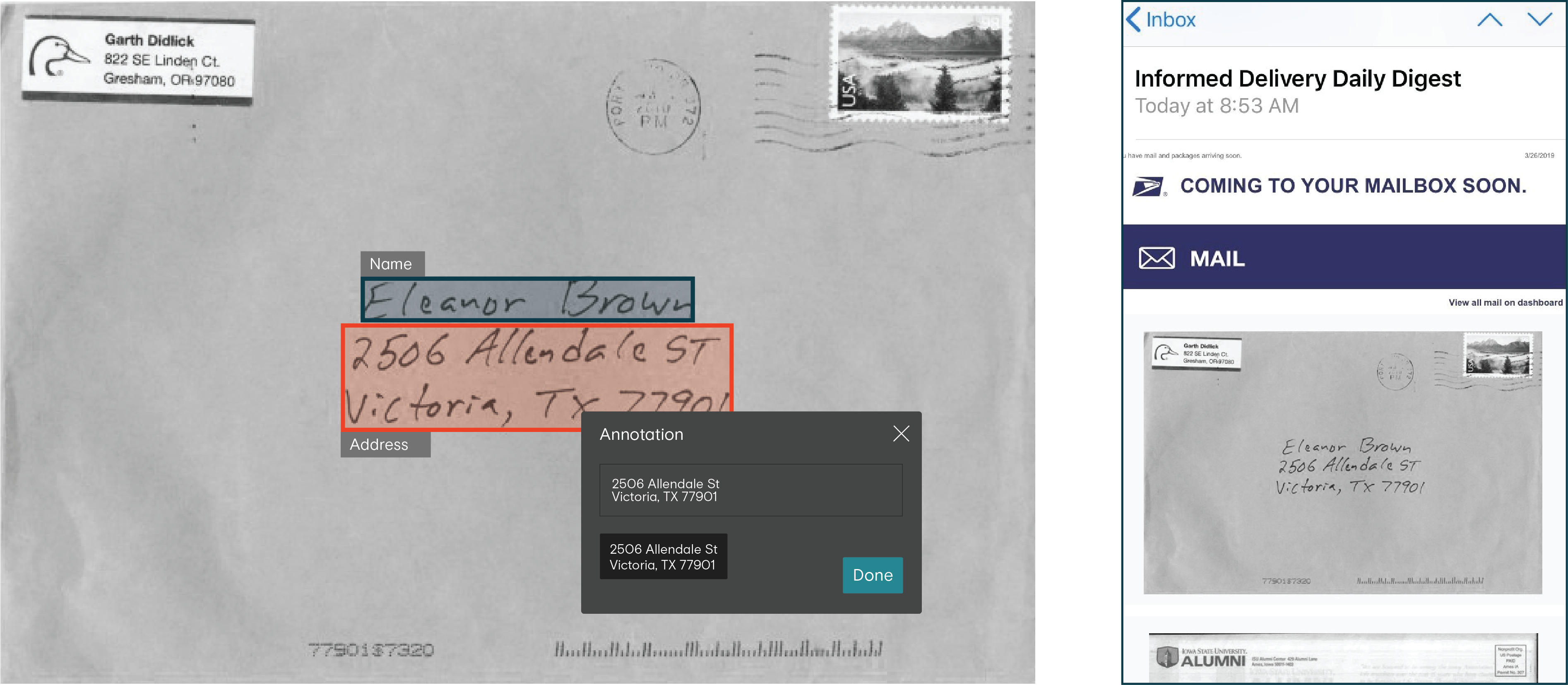
The OCR system does not just process the sorting of mail. 27.5 million people use USPS’ Informed Delivery service, which sends participants daily photographs of each piece of mail expected to arrive in your mailbox. Combining OCR with Machine Learning allows each photograph to be automatically organized by name and address then connected to the proper Informed Delivery account to ensure people only receive photos of their mail, and not somebody else’s.
Malicious Intent and Code Phrases
A potential instance of OCR teamed with NLP is in defending against criminal activity perpetrated by incarcerated individuals. Currently, in the prison system each piece of mail sent is read by a human to detect any malicious intent or signs of criminal activities. However, since the incarcerated individuals know their letters are being read, these activities are written in code. This leaves all the responsibility on the prison employees to detect hidden codes in prisoners’ mail. ML algorithms hold a much larger repository of code phrases comparatively. Then as the algorithms collect more samples, they can also begin detecting new anomalies to continuously be retrained as code phrases change.
What Makes Figure Eight Federal’s Process Different?
We Meet You Wherever You Are in The AI Process
Unfortunately, often when people employ these OCR systems, they do not team it with an AI algorithm. They input a large quantity of data at the beginning to train their OCR system, but then do not funnel the peer review corrections and constant incoming flow of new data samples back into the model to let it learn and infer more information for the future.
We can both integrate into your existing process or build your model from scratch. Even the most legacy models have shown an increase in accuracy and speed, driving down associated cost.
Three Methods Figure Eight Federal Uses to Increase OCR Productivity
Pre-Labeling
Like the USPS’ current process, an ML model makes a first attempt at OCR before human contributors – or Humans-in-the-Loop (HITL) – review it. This immensely speeds up labeling because the people are not individually labeling, they are simply reviewing. For those agencies with an existing OCR process in place, we can either implement this tool into your existing model or provide our own.
Speed Labeling
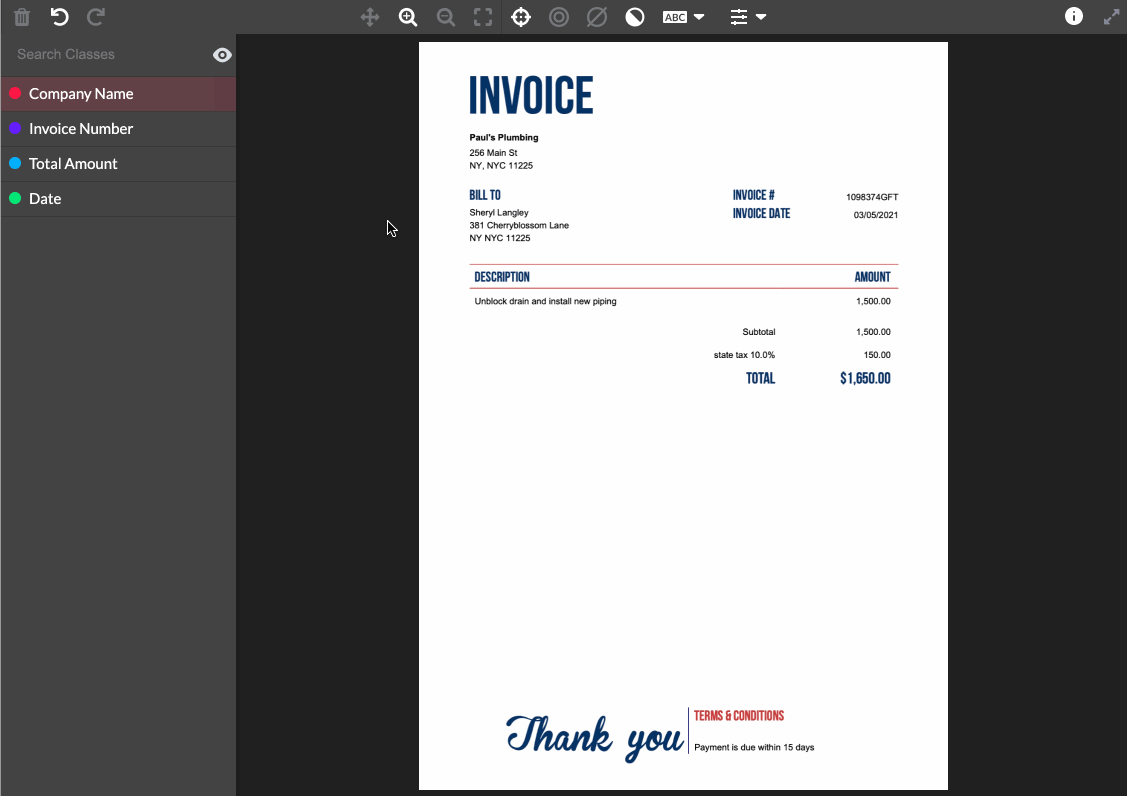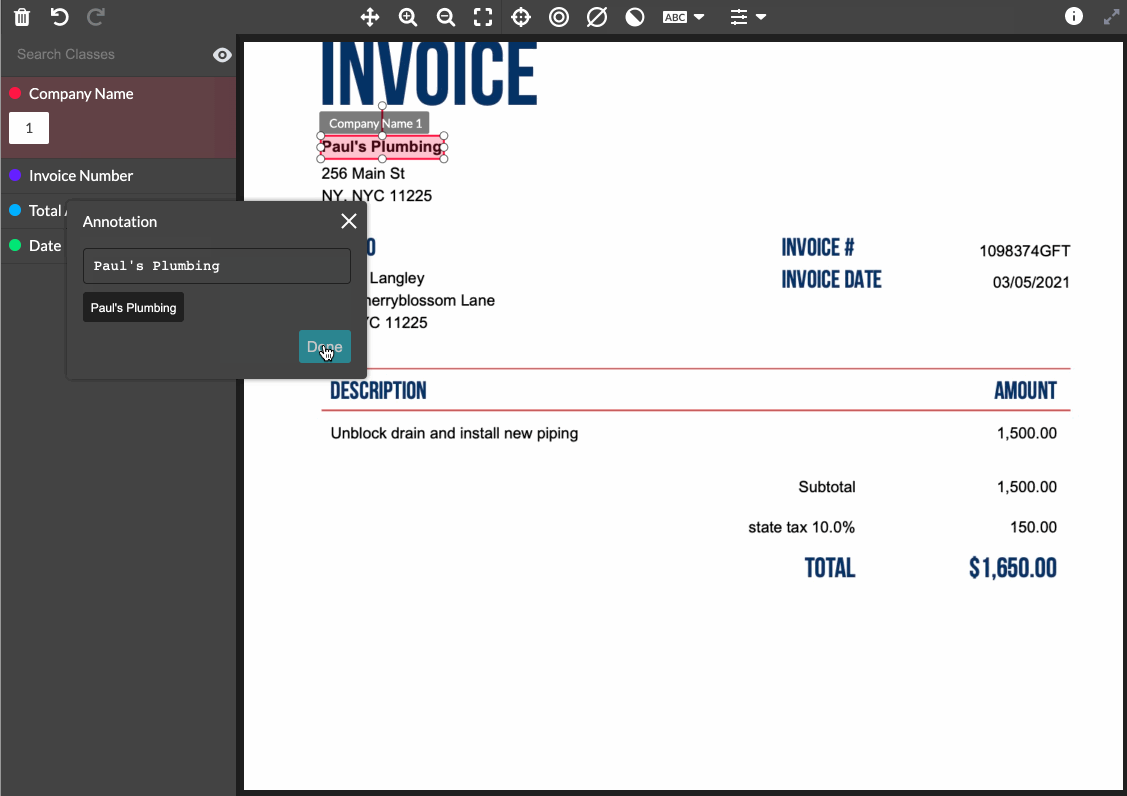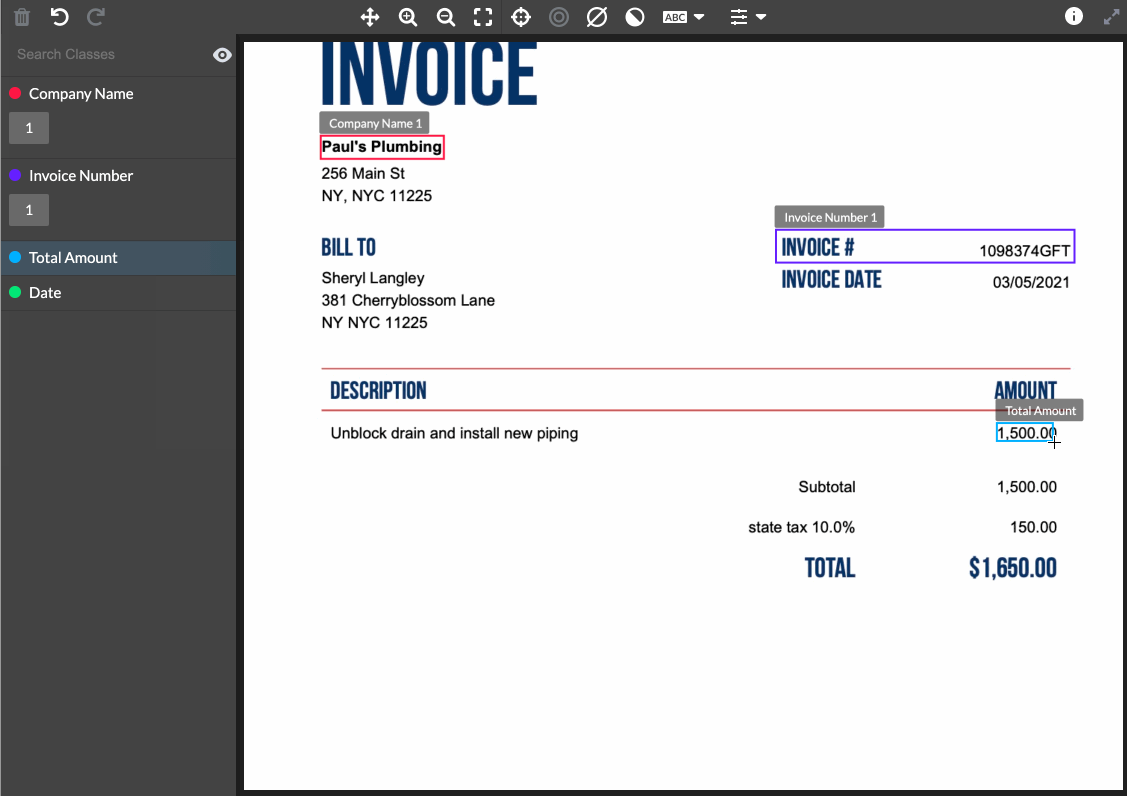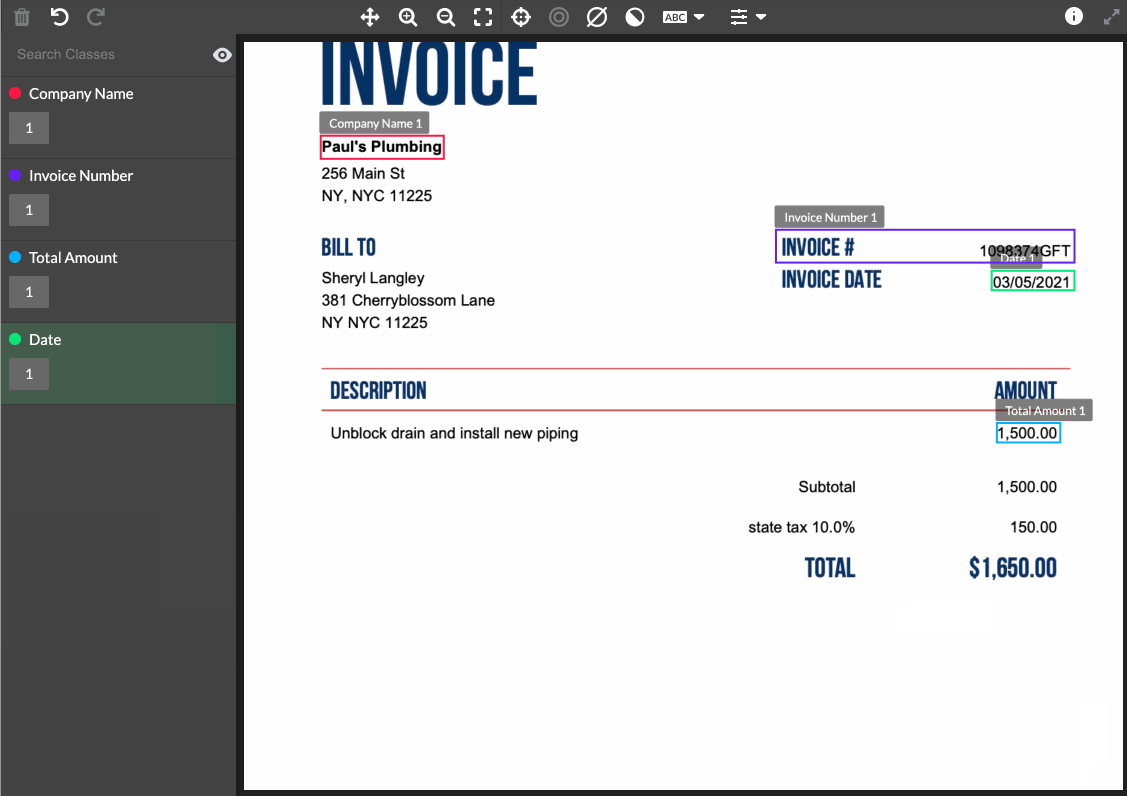
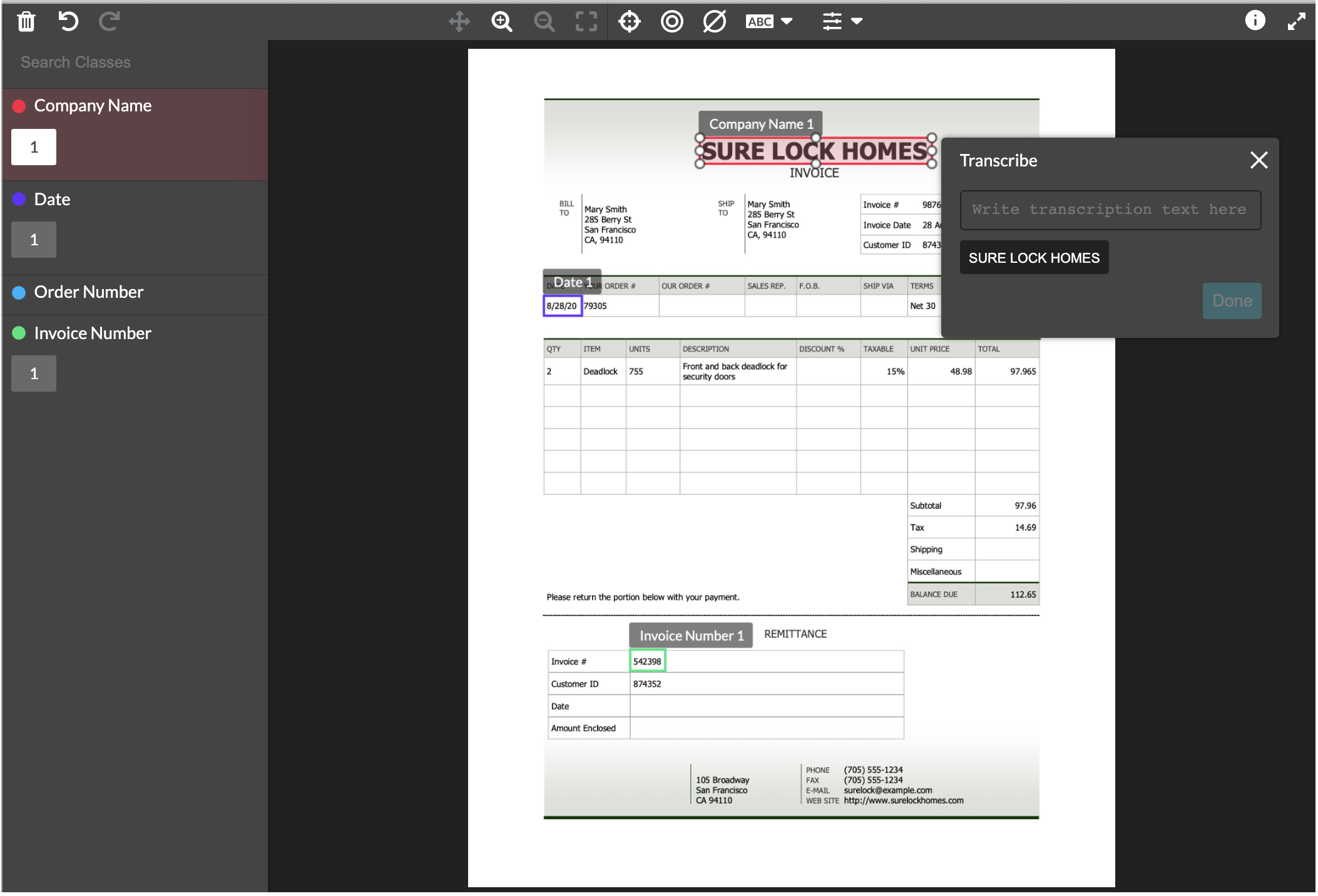
One flaw of most OCR applications, is they are not leveraging AI models alongside the human annotators. As computers create a bounding box around text in an image, our models can immediately predict the text selected. So instead of the labeler typing out each piece of text, they merely validate what the computer has generated in real time. This increases speed, while reducing cognitive load on labelers allowing them to process more data in the same duration as before.
Smart Validators
After people label the data, the ML models can also provide their own peer review to constantly test and verify the human judgements to ensure the highest quality of judgements without the need for a second team to review human generated labels.
These three pieces are critical to creating a higher performing model in a shorter period.
OCR FAQ’s We Hear at Figure Eight Federal
Will it really improve the accuracy and speed of my process?
Through our ML-assisted translation tool, full document transcriptions happen 5x faster than by employees alone.
What languages can you translate the text from?
With our pool of over a million annotators, we can handle translation for over 180 languages with native fluency.
Can we understand the meaning of [xyz] document type?
Yes. Not only will Figure Eight Federal optimize your non text data into text, but we also work with you to provide a custom Machine Learning algorithm via NLP to extract the exact data points valuable to your mission objectives.
Why Hire Figure Eight Federal
Figure Eight Federal harnesses the process of translating non-text documents into text, implementing an AI model to continuously improve the process and generate useful inferences from the data. Without Figure Eight Federal, agencies must hire three separate entities.
- A company that specializes in OCR to translate the images into text data.
- A company with ML programs for NLP that can learn and understand what the text means.
- A company with a pool of data annotators to validate the ML algorithms’ text predictions.
Figure Eight Federal has the capability to accomplish all three in one platform. We already have the OCR models ready to read your data; we work with you to develop a custom ML algorithm solution for you to continuously learn and improve your process; we use NLP to extract the valuable information from your data (and translate it into over 180 languages); and we have a crowd of over a million annotators who can validate the machine labeled outputs.
Schedule a demo with Figure Eight Federal and how OCR will extract value from your data.